模型蒸馏:大模型知识迁移的关键技术
模型蒸馏:大模型知识迁移的关键技术
在深度学习领域,随着模型规模的不断扩大,如何在保持模型性能的同时降低计算开销已成为一个亟待解决的问题。模型蒸馏技术应运而生,它通过将大型复杂模型(教师模型)的知识转移到小型简单模型(学生模型)中,实现了模型的轻量化部署。
这项技术最早由Geoffrey Hinton等人在2015年提出。其核心思想是:利用训练好的大模型输出的软标签来指导小模型的学习,使得小模型能够获得与大模型相近的性能。这种方法特别适用于当前大语言模型(LLM)的部署场景。
以大语言模型为例,一个拥有1750亿参数的模型需要约350GB的GPU内存,即使是仅有1000万参数的较小模型也需要20GB左右的GPU内存。如此庞大的资源需求使得这些模型在实际应用中面临严重挑战,尤其是在需要近实时响应的场景中。
模型蒸馏为这一问题提供了有效的解决方案。通过蒸馏技术,我们可以:
- 显著降低模型部署成本
- 提高推理速度
- 实现模型定制化
- 提升环境友好性
这种优化使得基础模型能够更广泛地应用于各类实际场景,既保证了效果,又实现了成本效益的平衡,为企业特别是拥有专有数据的公司提供了切实可行的解决方案。
模型蒸馏的架构与处理过程
基本组成要素
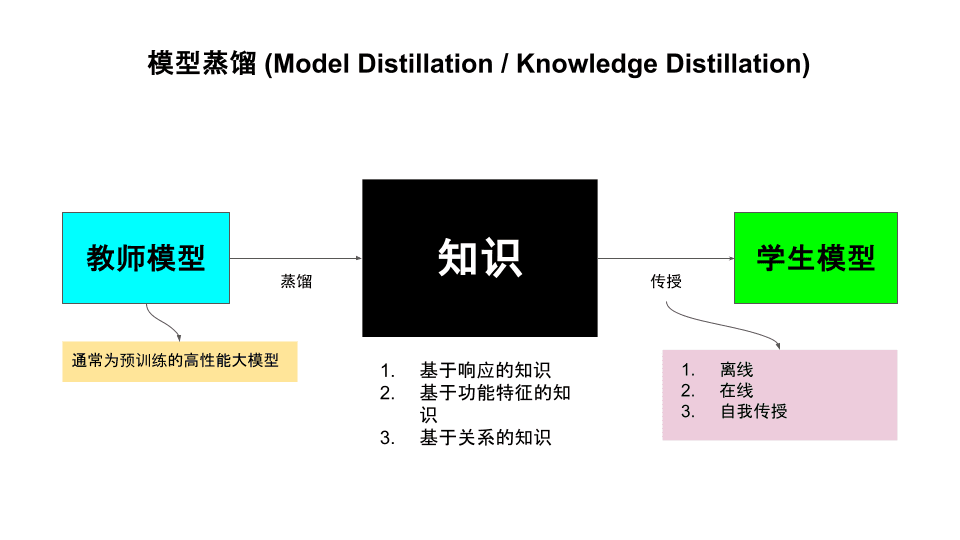
模型蒸馏的核心架构包含两个关键角色:教师模型(teacher model)和学生模型(student model)。教师模型通常是一个经过充分训练的大型模型,具有较高的准确性;而学生模型则是一个更为紧凑、资源消耗更少的小型模型。这种架构设计使得知识能够从复杂模型向简单模型进行有效转移。
模型架构选择
在进行模型蒸馏时,架构选择是一个重要的决策点。特别是对于学生模型,其架构可以有多种选择:
- 可以是教师模型的简化版本
- 可以是量化后的模型版本
- 也可以是一个完全不同但经过优化的网络结构
这种灵活性使得我们能够根据实际应用场景的需求,选择最适合的学生模型架构。
蒸馏过程
蒸馏过程本质上是一种特殊的监督学习。在这个过程中,学生模型通过学习教师模型的行为特征来获取知识。具体而言,学生模型会尽量减小自身预测结果与教师模型预测结果之间的差异。
这种学习方式与传统的监督学习有所不同:
- 传统监督学习使用真实标签作为学习目标
- 而蒸馏过程则使用教师模型的输出作为学习信号
- 这使得学生模型不仅能学习到正确的分类结果,还能获取教师模型内部的知识表示
通过这种方式,小型的学生模型能够在保持较高性能的同时,实现更高效的部署和应用。
训练方法
在模型蒸馏中,选择合适的训练方法对于知识迁移的效果至关重要。主要有三种训练方法:
离线蒸馏 (Offline Distillation)
- 使用预训练好的、参数冻结的教师模型
- 允许工程师在部署前评估模型性能和分析错误
- 是大多数团队的首选方法,特别是在使用响应式蒸馏时
在线蒸馏 (Online Distillation)
- 同时训练教师模型和学生模型
- 可以实现动态的知识迁移
- 训练过程更加灵活
自蒸馏 (Self-Distillation)
- 使用同一个网络同时作为教师模型和学生模型
- 适用于数据有限的环境
- 需要能够复制和更新模型
- 局限性:不适用于专有模型或未公开权重和架构的模型
选择合适的训练方法需要考虑项目的具体约束和目标。
模型蒸馏中的知识类型
知识蒸馏可以根据传递的知识类型分为三类。以下表格详细列出了各类型的特点及其优缺点:
| 蒸馏类型 | 主要特点 | 优点 | 缺点 |
|---|---|---|---|
| 响应式蒸馏 (Response-Based) | 学生模型模仿教师模型的预测输出,通过最小化两者输出差异来学习 | 实现简单,适用范围广,可应用于各种模型和数据集 | 仅传递输出相关知识,无法捕获复杂的内部表示 |
| 特征式蒸馏 (Feature-Based) | 学生模型学习教师模型的内部特征表示,通过最小化两者特征之间的距离来学习 | 有助于学习鲁棒的特征表示,可跨任务和模型应用 | 计算开销大,不适用于教师模型内部表示难以迁移的任务 |
| 关系式蒸馏 (Relation-Based) | 传递输入和输出之间的关系知识,使学生模型理解数据之间的内在联系 | 能学习到鲁棒且可泛化的输入输出关系,捕获更深层次的知识 | 计算资源需求高,实现难度大,需要工程师具备较高经验 |
蒸馏的好处
相比直接使用大语言模型或大规模视觉模型,模型蒸馏技术能够带来诸多优势。以下是主要的好处:
训练效率提升
模型蒸馏能够显著提高数据使用效率:
- 预训练和微调阶段所需的数据量更少
- 符合以数据为中心的AI理念
- 能够最大化数据的使用价值
部署效率优化
蒸馏后的模型具有明显的部署优势:
- 模型体积更小,运行更高效
- 特别适合资源受限的平台
- 在边缘计算和实时处理等场景中表现出色
性能改进
在特定任务和领域中:
- 类似于微调过程,可以提升模型的准确性
- 蒸馏后的小型模型能达到与大模型相近的性能
- 同时具备更快的响应速度
资源优化
从资源利用的角度来看:
- 显著降低计算和存储需求
- 减少项目整体成本
- 符合可持续发展和道德AI的发展策略
- 特别适合预算有限的项目